DevOps⚓︎
Overview⚓︎
The DevOps Microservice is an ODM Platform module dedicated to the management of a data product lifecycle.
Specifically, it implements the logic that allows users to handle the lifecycle of a Data Product Version in terms of DevOps operation. It exposes a set of APIs to handle all the set of operations needed to promote the data product to a particular lifecycle phase (e.g., dev, test, production, ...).
This microservice makes use of the Utility Plane modules to interact with specific DevOps tools offered by the infrastructure for pipeline execution.
Concepts⚓︎
Lifecycle⚓︎
The data product lifecycle encompasses the stages involved in creating, developing, deploying, managing, and decommissioning data products.
The descriptor of a data product is designed to have a lifecycleInfo section dedicated to the data product evolution specification. In particular, the lifecycle section contains information about Activities and Tasks (see their definitions below) of a Data Product Version.
Stage⚓︎
In the data product lifecycle, a Stage represents each distinct phase of the data product delivery (e.g., development, testing, deployment, production, ...).
Activity⚓︎
An Activity is a set of one or more Tasks (see their definition below) that represent a stage transition in the lifecycle of a Data Product Version.
For example, an Activity could be a set of Tasks in charge of deploying the Data Product Version in its dev stage.
In ODM, an Activity is created through:
- Data Product ID
- Data Product Version
- Stage
Task⚓︎
A Task is a single execution point of an Activity, such as a pipeline run on a DevOps tool.
An Activity without tasks cannot exist. Upon the creation of an Activity, a Task is always created.
Callback⚓︎
A Task must return a callback to the DevOps server when its execution finishes in order to provide the execution results. The callback URL is automatically generated by the DevOps server and then passed to the specific executor in a parameter named callbackRef.
The body of the callback is optional: if it's not present, the DevOps server will assume that the Task is in a successful state; if it is present, it must have the following format:
where:<status>could be one ofPROCESSEDorFAILED<errors>is an optional string with the error encountered while executing the Task<results>is an optional JSON object with any kind of depth- only one of
errorsandresultsmust be given
The body of the callback will be stored in the Task results.
Task Context⚓︎
The DevOps Microservice allows combining the Data Product descriptor and a specific usage of the callback feature to enrich a Task with a Context. The Context of a Task is a recap of the status and the results of each previous Task of the same Activity and of each Task of an eventual previous Activity. It allows a Task to access results from previous ones and, if explicitly declared, use them as parameters for the execution.
A Context is created every time a Task execution is triggered. The context it's then forwarded to the Executor Adapter that will handle the execution by using the context parameters as needed.
How it works⚓︎
Architecture⚓︎
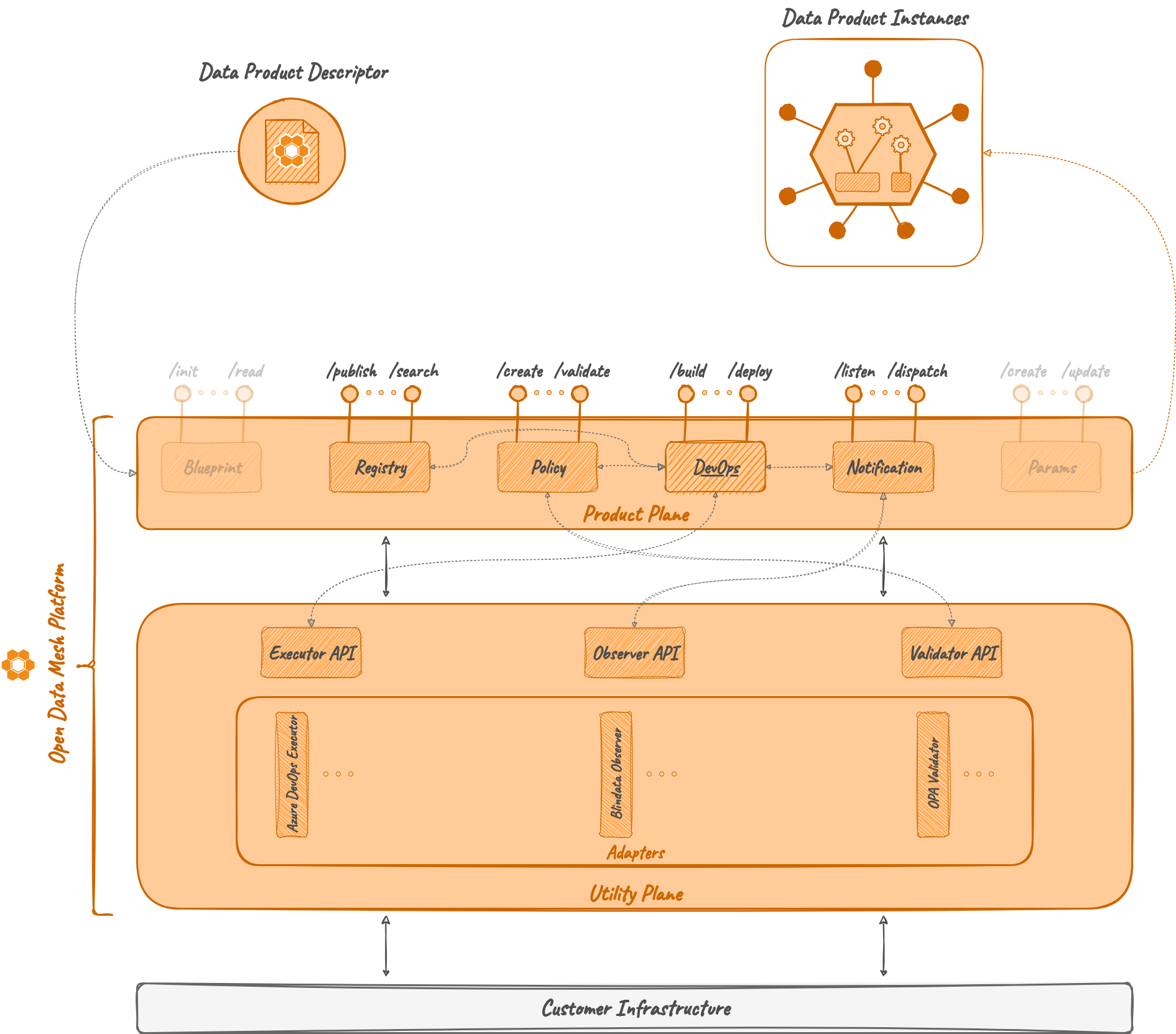
As the majority of the ODM services, the DevOps Microservice is composed of two modules:
- DevOps API: a module containing abstract controllers, Java resource definitions, and a client to interact with the controller.
- DevOps Server: a module implementing the abstract controllers, any component useful to interact with the DB (entities, mappers, repositories, ...), and services needed for DevOps operations.
Relations⚓︎
As previously stated, the DevOps service is not meant to be a standalone microservice. In order to properly operate as an orchestrator for DevOps operations, it requires:
- Registry Server: to retrieve Data Product Version objects
- Executor adapters: to invoke the execution of Tasks on the correct target DevOps tool
In addition, it could also have optional interactions with:
- Policy Service: to optionally validate stage transitions and Tasks and Activity results
- Observer APIs: to optionally send policy evaluation events and/or stage transition events
Registry⚓︎
The creation of an Activity, including its Tasks, requires a reachable instance of the Registry Server to fetch the content of the Activity. The DevOps server will start even without a reachable Registry Server, but every creation will return an error.
Executor⚓︎
The execution of an Activity requires an active instance of the chosen Executor Adapter. Each Activity could be potentially executed on a different DevOps provider, adding multiple adapters to the requirements. So, the number of Executor Adapters that the DevOps microservice needs to know depends on the desired user behaviour.
Observer⚓︎
Warning
This section describes code that is still evolving.
The DevOps Microservice has an Observer system based on the Observer Design Pattern. On the application startup, every notification listener listed in the property file is registered and, when an event occurs, a dispatcher sends the notification to every active listener.
The following are the events handled by the DevOps microservice:
- DATA_PRODUCT_STAGE_TRANSITION
- DATA_PRODUCT_TASK_RESULTS
- DATA_PRODUCT_ACTIVITY_RESULTS
Policy⚓︎
Warning
This section describes code that is still evolving.
The DevOps Service is able to interact with the Policy Microservice to check:
- validity of a stage transition: upon an Activity start future and previous stages are checked
- compliance of Task results:
- the Task results are returned within a callback
- e.g., validating a Terraform plan returned in the callback before proceeding with the next Task or with the closing of the Activity
- compliance of Activity results
- the result of an Activity is the combination of the results of each of its Task
- the full set of results could be evaluated
- when an Activity ends successfully, it's possible to evaluate whether the exposed services are coherent or not with the initial contract
As shown in the dedicated section, the policies can have a special tag to specify:
- the phase in which the policy must be evaluated,
- whether the evaluation result is blocking or not for that phase.
A policy configured to be blocking and evaluated with a negative result, will lead to the failure of the relative phase.
Examples⚓︎
Lifecycle Configuration⚓︎
The descriptor of a data product is designed to have a lifecycleInfo section dedicated to the data product evolution specification. In particular, the lifecycle section contains information about Activities and Tasks of a Data Product Version.
To briefly describe how the lifecycle section works, let's consider the following example:
{
...,
"internalComponents":{
"lifecycleInfo":{
"dev":[
{
"service": {
"$href":"azure-devops"
},
"template":{
"specification":"spec",
"specificationVersion":"2.0",
"definition":{
"organization":"[organizationName]",
"project":"[projectName]",
"pipelineId":"[pipelineID]",
"branch":"master"
}
},
"configurations":{
"params":{
"paramOne":"Hello World"
}
}
}
],
"prod":[
{
"service":{
"$href":"azure-devops"
},
"template":{
"specification":"spec",
"specificationVersion":"2.0",
"definition":{
"organization":"[organizationName]",
"project":"[projectName]",
"pipelineId":"[pipelineID]",
"branch":"master"
}
},
"configurations":{
"params":{
"paramOne": "Value of paramOne",
"paramTwo": "Value of paramTwo"
}
}
}
]
}
}
}
dev and prod.
Each of them is composed of a single Task, which make use of Azure DevOps as DevOps service. This means that in order to execute each Task, a specific Executor called azure-devops must be registered on the DevOps Service startup (as shown in the section below).
Each Task has a mandatory template attribute that is a JSON object containing a definition attribute showing how to execute the Task. In the example, the Tasks are pipelines executed on Azure DevOps and the definition contains information to identify them. In addition to this, each Task could also have a configuration attribute with extra information, such as parameters for the pipeline, needed for the execution.
The content of both attributes is strictly dependent on the implementation of the Executor Adapter that will handle the Tasks. The example above shows a possible implementation to work with the Azure DevOps Executor.
Registry Server Configuration⚓︎
To make sure to correctly configure the interaction among them, check the presence of the following configurations in the property file of the active Spring profile before running the service:
Executor Adapters Configuration⚓︎
To make sure to correctly configure the interaction with the Executor Adapters, use the following configuration in the property file of the active Spring profile before running the microservice:
odm:
utilityPlane:
executorServices:
azure-devops:
active: true
address: http://<hostname>:<port>
checkAfterCallback: false
azure-devops as service in the lifecycle section of a Data Product descriptor. To configure more than one executor, add another block under the executorServices attribute.
If the specific DevOps tool exposes an API to check the status of a pipeline, this API can be called via the Executor Adapter specific implementation. This behaviour can be enabled or disabled through the checkAfterCallback property. If this property is set to true, the check will always be executed.
Notification Adapters Configuration⚓︎
To make sure to correctly configure the interaction with the Notification Adapters, use the following configuration in the property file of the active Spring profile before running the microservice:
odm:
utilityPlane:
notificationServices:
<notificationListenerName>:
active: true
address: http://<hostname>:<port>
notificationServices attribute.
End-to-end Example⚓︎
To make all the concepts clearer, let's explain them step by step through the following example.
Consider a Data Product Version with two Stages. Each stage is associated with an Activity that has, respectively, two Tasks and one Task.
This is the lifecycleInfo section of the data product descriptor:
{
...,
"lifecycleInfo": {
"dev": [
{
"service": {
"$href": "azure-devops" // AzureDevOps Executor Adapter required
},
"template": {
"specification": "spec",
"specificationVersion": "2.0",
"definition": {
// references for the AzureDevOps pipeline
}
},
"configurations": {
"stageToSkip": [],
"params": {
// parameters for the AzureDevOps pipeline
}
}
},
{
"service": {
"$href": "azure-devops"
},
"template": {
"specification": "spec",
"specificationVersion": "2.0",
"definition": {
// references for the AzureDevOps pipeline
}
},
"configurations": {
"stageToSkip": [],
"params": {
// parameters for the AzureDevOps pipeline
}
}
}
],
"test":[
{
"service":{
"$href":"azure-devops"
},
"template":{
"specification":"spec",
"specificationVersion":"2.0",
"definition":{
// references for the AzureDevOps pipeline
}
},
"configurations":{
"stageToSkip": [],
"params": {
// parameters for the AzureDevOps pipeline
}
}
}
]
},
...
}
The first Activity aims to deploy the Data Product Version in the dev stage, while the latter has the goal to promote the product to the test stage. Let's assume that inside the dev stage, the first Task is provisioning the infrastructure and the second one is deploying an application on that infrastructure.
When the DevOps server receives the request to execute the first Activity, it extracts all the Tasks from the Activity. Then, it is ready to sequentially forward the Task execution request to the right Executor Adapter. Before forwarding the request to the Executor Adapter, the DevOps service enriches the Task with a Context.
For the first Task of the first Activity, the Context will be:
and theconfigurations attribute of the Task will become:
{
...,
"configurations": {
"params": {
// parameters for the AzureDevOps pipeline
},
"context": {
"dev": {
"status": "RUNNING",
"finishedAt": null,
"results": null
}
}
}
}
When the first Task of the first Activity finishes its execution (let's assume with a successful state), it forwards a callback to the DevOps server communicating its status and any result obtained during the execution (e.g., the IP address to access a VM in the provisioned infrastructure).
The callback body can be something similar to:
When a callback from the DevOps tool is received, it is processed and the results are stored in the database.
Now, the request for the second Task can be submitted as well. The DevOps service takes the second Task, enriches it with the Context of the first one, and forwards it to the Executor Adapter. The Context now becomes:
{
"dev": {
"status": "RUNNING",
"finishedAt": null,
"results": {
"task1": {
"vm": {
"name": "vm-dev",
"ip": "198.168.20.120"
}
}
}
}
}
configurations attribute of the Task will become:
{
...,
"configurations": {
"params": {
// parameters for the AzureDevOps pipeline
},
"context": {
"dev": {
"status": "RUNNING",
"finishedAt": null,
"results": {
"task1": {
"vm": {
"name": "vm-dev",
"ip": "198.168.20.120"
}
}
}
}
}
}
}
After the second Task of the first Activity finishes its execution with a successful state, it forwards a callback to the DevOps server communicating its status and, for example, a Hello World endpoint URL of the deployed application. The callback body is:
Finally, the DevOps server receives a request to execute the second Activity of the same Data Product Version. It extracts the single Task repeating the same operations showed above.
This time, the context and the enriched Task (only its configurations attribute is shown) will be:
{
"dev": {
"status": "PROCESSED",
"finishedAt": "2023-11-23 14:32:00",
"results": {
"task1": {
"vm": {
"name": "vm-dev",
"ip": "198.168.20.120"
}
},
"task2": {
"url": "localhost:8121/helloWorld"
}
}
},
"test": {
"status": "RUNNING",
"finishedAt": null,
"results": null
}
}
{
...,
"configurations": {
"params": {
// parameters for the AzureDevOps pipeline
},
"context": {
"dev": {
"status": "PROCESSED",
"finishedAt": "2023-11-23 14:32:00",
"results": {
"task1": {
"vm": {
"name": "vm-dev",
"ip": "198.168.20.120"
}
},
"task2": {
"url": "localhost:8121/helloWorld"
}
}
},
"test": {
"status": "RUNNING",
"finishedAt": null,
"results": null
}
}
}
}
In this way, each Task can potentially access any previous result in the Data Product Version DevOps lifecycle.
Considering the same example, how can the Context be used? Suppose that the second Task of the first Activity requires the IP of the provisioned infrastructure to deploy the application, and the Task of the second Activity needs to know the URL of the application endpoint. Through a specific syntax, it's possible to encode directly in the Data Product descriptor a placeholder variable whose value would be retrieved from the context. The JSON descriptor will be similar to:
{
...,
"lifecycleInfo": {
"dev": [
{
"service": {
"$href": "azure-devops" // AzureDevOps Executor Adapter required
},
"template": {
"specification": "spec",
"specificationVersion": "2.0",
"definition": {
"organization":"mycustomorg",
"project":"mycustomproject",
"pipelineId":"2",
"branch":"master"
}
},
"configurations": {
"stageToSkip": [],
"params": {
"param1": "value1",
"param2": "value2"
}
}
},
{
"service": {
"$href": "azure-devops"
},
"template": {
"specification": "spec",
"specificationVersion": "2.0",
"definition": {
"organization":"mycustomorg",
"project":"mycustomproject",
"pipelineId":"3",
"branch":"master"
}
},
"configurations": {
"stageToSkip": [],
"params": {
"param": "value",
"vmIp": "${dev.results.task1.vm.ip}"
}
}
}
],
"test":[
{
"service":{
"$href":"azure-devops"
},
"template":{
"specification":"spec",
"specificationVersion":"2.0",
"definition":{
"organization":"mycustomorg",
"project":"mycustomproject",
"pipelineId":"6",
"branch":"master"
}
},
"configurations":{
"stageToSkip": [],
"params": {
"param": "value",
"endpointURL": "${dev.results.task2.url}"
}
}
}
]
},
...
}
Thanks to this strategy, the Executor AzureDevOps, and, generally, every other Executor Adapter, can replace the placeholder for the variable with values from the context.
In this scenario, the Azure DevOps pipeline of the second Task of the dev Activity can use a vmIp parameter, as well as the pipeline for the Task of the test Activity can use an endpointURL parameter.
Technologies⚓︎
Other than the default Java, Maven and Spring technologies, the DevOps module does not make use of any particular technology.
References⚓︎
- GitHub repository: odm-platform
- API Documentation: DevOps Server API Documentation